Below are descriptions of some of my data science projects. You can also click on the titles for links to the code on github.
Recommendation system for rock climbing routes
mountainproject.com is a website that provides information about rock climbing areas and allows users to rate climbing routes. Using data that I scraped from Mountain Project, I built a collaborative-filter recommender system that recommends new routes in The Shawangunks (Gunks) in upstate New York. I also built a climbing partner finder that pairs climbers based on their climbing preferences.
I examined 470 routes in the Gunks which were rated by about 2,400 climbers for a total of about 31,000 ratings.
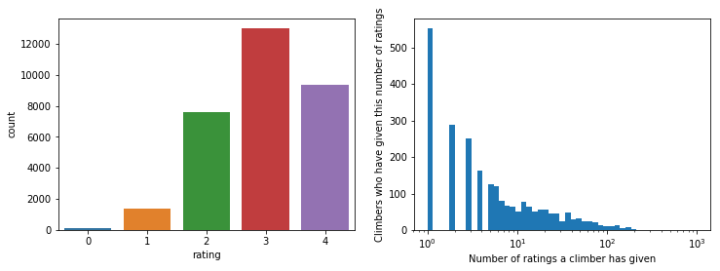
Using the collaborative-filtering library surprise, I trained a k-nearest neighbor estimator to predict the ratings that climbers would give to routes they have not climbed yet. This can then be used to rank the top N climbs to suggest to each climber. The root-mean-square error (RMSE) for the final model was 0.62. This can be compared to the baseline RMSE of 0.87 that I get if I just use the average rating of all climbing routes.
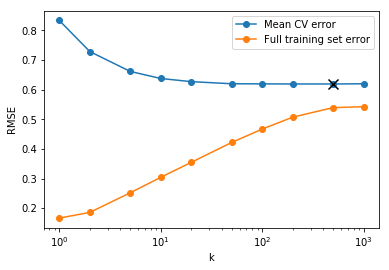
In addition, the k-nearest neighbors works by calculating the similarity between climbers (for a user-based similarity calculation) or the similarity between climbing routes (for an item-based similarity calculation). This allows us to suggest climbing partners by ranking climbers that are most similar. Or, if a climber is looking for new routes that are most like a given route, the item-based similarity can suggest the most similar routes. Examples of these rankings can be found in this notebook.
Predicting Rossmann store sales
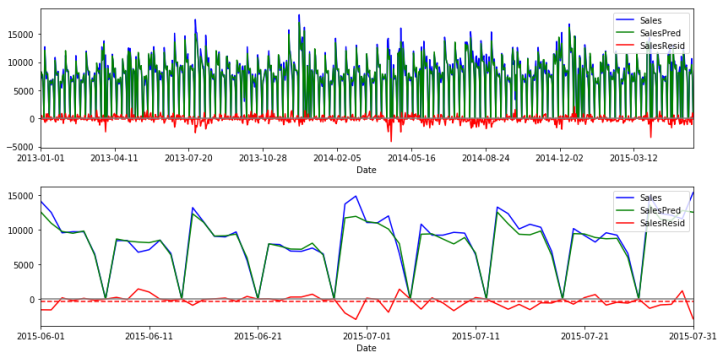
Rossmann is a European drug store chain based in Germany. Using a dataset for the daily sales in each of ~1000 stores over approximately three years, I built a model that can predict daily sales in each store 6 weeks in advance. This was part of a Kaggle competition. Below is an example of the predicted sales for my model compared with the actual sales in one of the stores.

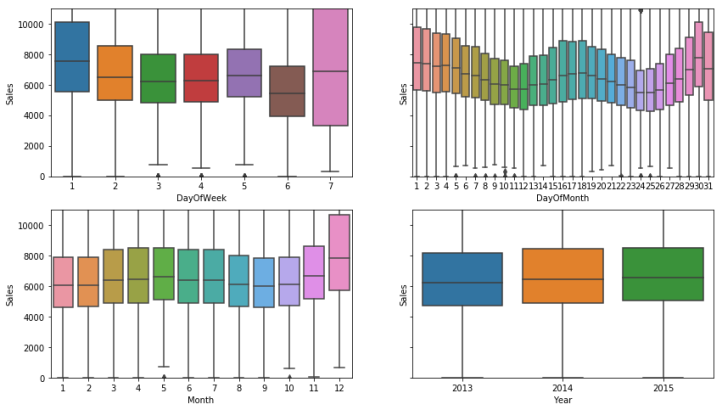
In addition, there are other quantities that predict the sales such as a promotion on a given day, the layout of the store, and whether or not a given day is a state holiday or school holiday.
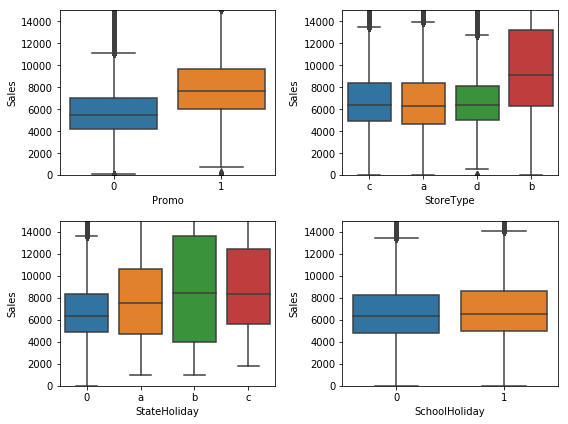
I trained a Random Forest Regressor using these features (as well as a couple others). To do this, I broke up the data into a training set, and left out the last 2 months as a validation set. I chose the hyperparameters of the Random Forest model that minimized the fractional RMSE on the validation set. I was able to a achieve a RMSE of 13.5%. The current best score is 10%.
Ranking loans from Lending Club
Using a dataset from the peer-to-peer lending company Lending Club, I built a model to predict the expected ROI on unsecured 3-year personal loans. With this model I then made a recommender that ranks borrowers within a grade based on their expected ROI so that lenders can invest in the most profitable loans.
- Data cleaning: This involved selecting features such as loan purpose, home ownership, income, and past delinquencies, and removing any features that were not available at the time the loan was issued. I then performed imputation on missing data and one-hot-encoding for categorical data.
- Predict defaults: I used a random forest classifier to predict if a borrower would default. Because only 8%-17% of borrowers default, the data set is imbalanced. I therefore used the F1 score which balances precision and recall to optimize the random forest hyperparameters.
- Calibrate default probability: As a result of the data imbalance, the classifier’s probability estimator massively underestimates the actual frequency of defaults for a test-set. So, I recalibrated the probability estimator.
- Estimate recovery of defaulted loans: For loans that do default, lenders will still be able to recover some of the owed amount. I performed regression to estimate the fraction of the loan that would be recovered. After trying multiple algorithms (e.g. linear regression, support vector regression, random forests) I found that none of them were were accurate than simply predicting the mean recovered value of 42%, so I concluded that there was very little information left in the data, and just used the mean value.
- Predict ROI: With the calibrated model for default probability and the model for recovery of defaulted loans I then calculated the expectation value for the total amount paid back. This can then be translated to an annualized rate of return. With this the available loans can be ranked, and investors can choose the most profitable loans.
Tutorial on regression techniques
I made this tutorial on regression techniques using scikit-learn for a workshop on Reduced Order Gravitational-Wave Modeling held in June 2018. It covers linear models (Ridge, Lasso), kernel techniques (Kernel Ridge, Support Vector Regression, Gaussian Process Regression), Neural Networks, and tree-based fitting (Random Forest). The goal was to demonstrate regularization and cross-validation methods that let the data choose the complexity of the model.
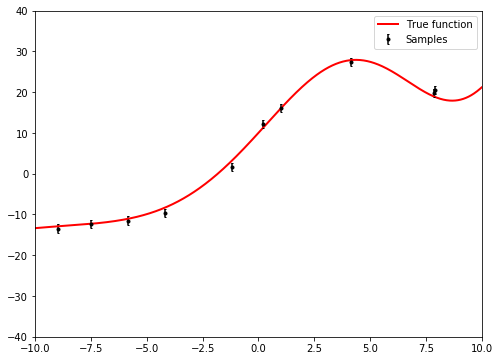
We want to fit this data with a parameterized function, and a standard function to try is a polynomial:

If we think of each power 


We can find the coefficients 



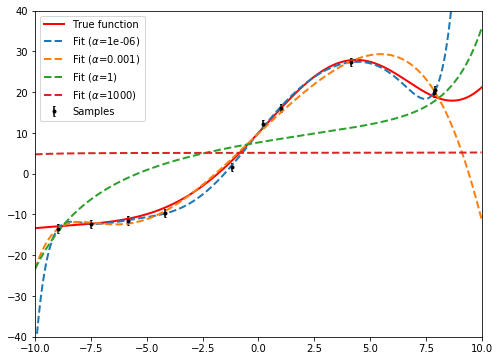
However, the standard question is: which order polynomial do we choose? If we choose a low order polynomial, the function won’t have enough complexity to accurately fit the data. If we choose a high order polynomial, the function will be overfit and won’t generalize to new data. As an example, below is an 11th order polynomial (12 free coefficients) fit to the 10 data points. The system is technically underdetermined and clearly overfits the data

Instead of using a lower order polynomial to avoid overfitting, we can instead place a penalty on the size of coefficients resulting in a simpler fitting function. This method is known as regularization. The cost function that is minimized has an additional term for the coefficients, and looks like

The larger the hyperparameter 
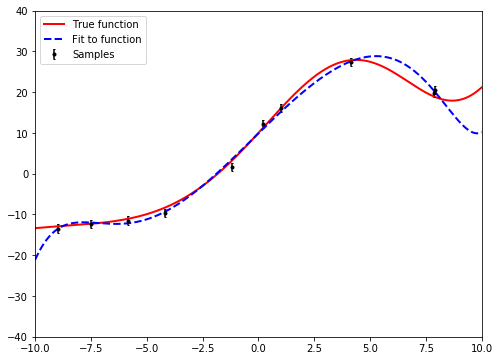
The optimal value of the hyperparameter
- Break the data into k sets.
- Fit the function with k-1 (training) sets. Calculate the error with the other (validation) set.
- Cycle through the sets so that each set is the validation set exactly once.
- Choose the hyperparameters that give the smallest average error for the validation set.
- Retrain on the entire training set with the chosen hyperparameters.
Below is the fitting function after the optimal value of
Predicting the sale prices of homes
The goal of this project is to predict the sale prices of houses in Ames, Iowa using a training set of sale prices and about 80 features of each house. I obtained a fractional RMSE of 14%. The current best score is 11%.

